On top of all that, you can add spider as well as downloader middlewares in between components as it can be seen in the diagram listed below. The code is really straightforward yet there are numerous efficiency and also use problems to solve prior to efficiently creeping a complete web site. Typical Crawl preserves an open database of web creep information. For instance, the archive from May 2022 contains 3.45 billion websites. Online search engine (e.g. Googlebot, Bingbot, Yandex Crawler ...) accumulate all the HTML for a substantial component of the Web. One more point to note is that this spider will certainly get the pages from the web page, yet will certainly not continue creeping after all those pages have actually been logged.
- Modern internet browsers such as Firefox and Chrome support you because job by a feature called "Evaluate Component", available through a right-click on the web page element.
- Large enhancements in information scraping from images as well as video clips will have significant effects for electronic marketing professionals.
- The entire point of a spider is to find as well as pass through web links to other web pages and also grab data from those web pages also.
- There is an open Scrapy Github concern that shows that external URLs do not obtain filtered out when OffsiteMiddleware is used before RedirectMiddleware.
- They used a data enthusiast to get web information needed to acquire insights into consumers as well as fads and concentrate on logical remedies for their customers.
Lots of individuals and companies can scratch news websites to remain existing on stories and issues appropriate to them. This can be especially useful if you are trying to create a feed of some type, or if you simply require to keep up with everyday records. If you have actually adhered to these steps, you must currently have the ability to see the data from the website laid out in your spreadsheet.
Benefit From Individual Representatives
A web crawler is a web robot or a program that aids in internet indexing. It browses through the internet in an organized manner and also seeks out components such as the key words in each page, the sort of web content it contains, the links, and so forth. After this, it gathers all this combined info and returns it to the internet search engine. This is the simplest means of describing the approach of internet crawling.
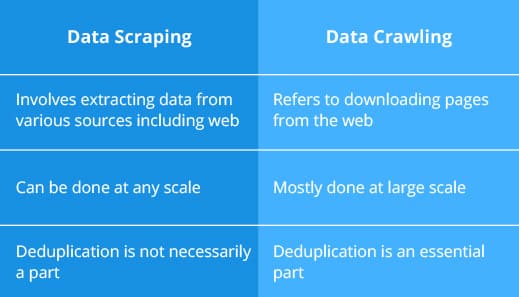
What is the distinction in between information scraping as well as information crawling?
Data creeping is a more comprehensive process of systematically discovering and also indexing data sources, while information scraping is a more particular procedure of removing targeted data from those sources. Both techniques can be used together to essence data from sites, databases, or various other resources.
Whether or not you are anticipating an absolute or loved one URL can be kept as a home of the Site things. Get complete access to Web Scraping with Python, second Version and 60K+ other titles, with a cost-free 10-day trial of O'Reilly. Aspects can be extracted in XML items with XPATH-expressions. Initially, make certain your functioning directory is the data directory site we offered the exercises. This is where you can include your API trick which will link up to your Browserless account and permit you to run your manuscript with Browserless.
Recent Articles:
Whenever we scuff a site we intend to try to make just one request per web page. We do not intend to be making a demand every time our parsing or other logic does not work out, so we require to parse just after we have actually saved the web page locally. The crawler starts with a solitary URL, finds links to the complying with pages, enqueues them, as well as proceeds until say goodbye to wanted links are available. As formerly gone over, among the primary constraints of HTML parsers is that they can not scratch dynamically produced content. Nevertheless, by combining the power of internet automation software with HTML parsers, we can exceed simple automation and also provide JavaScript to extract data from complicated web pages.
SciSciNet: A large-scale open data lake for the science of science ... - Nature.com
SciSciNet: A large-scale open data lake for the science of science ....
Posted: Thu, 01 Jun 2023 07:00:00 GMT [source]
So first you produce a spider which will certainly result all the page Links that you respect - it can be web pages that remain in a specific category on the site or in particular parts of the website. Or perhaps the URL needs to consist of some type of word for instance as well as you gather all those Links - and then you create a scraper which draws out predefined data areas from those pages. In addition to indexing the net, crawling can also gather information.
Producing The Spider
Gorgeous Soup is a Python library utilized to draw out HTML and XML elements from a web page with simply a few lines of code, making it the ideal choice to take on straightforward jobs with speed. It is likewise reasonably simple to set up, discover, as well as master, which makes it the excellent web scuffing device for novices. And also, you can automate your data removal as well as leave no trace using Octoparse's confidential proxy feature. That suggests your job will turn through tons of different IPs, which will certainly prevent you from being obstructed by certain web sites.
Currently we can utilize that function scrape_guardian_article in any other part of our manuscript. We use a running variable i, taking worths from 1 to size to access the single links in all_links and also create some development output. I wished this post on information scratching was interesting as well as interesting. There are endless opportunities as to what you can complete with web and also data scratching. While reviewing this short article you've possibly wondered, "what are some great use situations for web/data scuffing?
Producing An Internet Crawler With Nodejs
Particular web sites reject to give any kind of public APIs as a result of technological restrictions or other reasons. In such instances, some people might select RSS feeds, however I don't recommend using them because they have a number limitation. What I wish to talk about here is exactly how to construct a spider on our very own to deal with this circumstance.
https://maps.google.com/maps?saddr=545%20King%20St%20W%20Unit%20239%2C%20Toronto%2C%20ON%20M5V%201M1%2C%20Canada&daddr=2%20Bloor%20St%20W%2C%20Toronto%2C%20ON%20M4W%203E2%2C%20Canada&t=&z=15&ie=UTF8&iwloc=&output=embed
After you've situated and also normalized the Links on the search page, you have actually effectively minimized the trouble to the example in the previous section-- extracting data from a web page, given a website style. Obviously, the drawback is that you are quiting a specific quantity of flexibility. In the very first instance, each web site obtains its very own free-form function to choose and analyze HTML nonetheless needed, so as to get the end result.
Botanee to Double Revenue by 2026 as Chinese Skincare Giant ... - Yicai Global
Botanee to Double Revenue by 2026 as Chinese Skincare Giant ....
Posted: Thu, 13 Jul 2023 04:41:49 GMT [source]
What is the distinction between junking as well as crawling?
Internet scratching purposes to extract the information on web pages, and also internet crawling objectives to index and discover web pages. Internet Web scraping solutions for businesses crawling includes adhering to web links completely based on links. In contrast, web scuffing indicates composing a program computer that can stealthily gather data from several internet sites.